Infrastructure
That Never
Sleeps.
We architect, migrate, and manage enterprise cloud infrastructure on AWS, Azure, and GCP — with zero-downtime deployments, bulletproof security, and up to 40% cost reduction from day one.
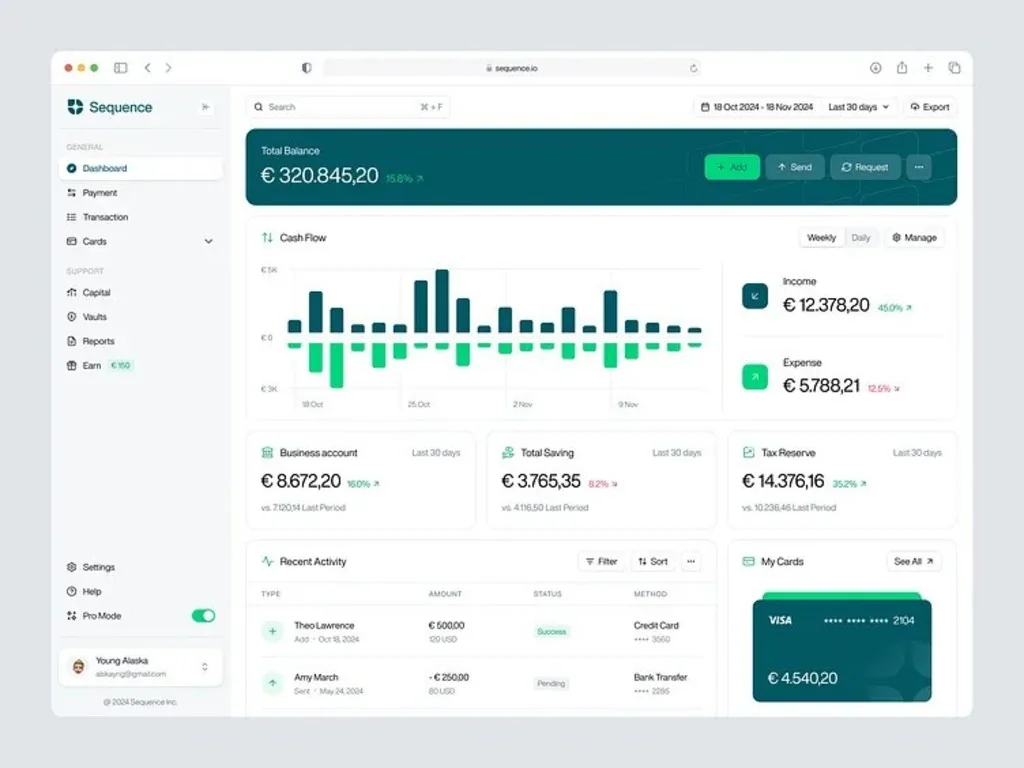
✓ Build completed 1.2s
✓ Tests passed 48/48
▶ Deploying to prod-us-east
✓ Zero downtime live
Every Layer.
Every Cloud.
Covered.
From initial cloud strategy to day-to-day infrastructure management — we handle the complexity so your team can focus on building product, not fighting servers.
Cloud Migration
Lift-and-shift or full re-architecture — we migrate your on-premise or legacy infrastructure to AWS, Azure, or GCP with zero data loss and minimal downtime.
24/7 Managed Infrastructure
Round-the-clock monitoring, incident response, and proactive maintenance. Your infrastructure never rests — and neither does our team when it matters.
CI/CD Pipelines
Automated build, test, and deploy workflows that cut release cycles from days to minutes. GitHub Actions, GitLab CI, Jenkins — and everything in between.
Kubernetes & Containers
Production-grade Kubernetes clusters on EKS, AKS, or GKE. Containerize your services with Docker and orchestrate them for high availability and auto-scaling.
Infrastructure as Code
Every resource defined, versioned, and reproducible in code with Terraform and Pulumi. No more snowflake servers — your entire cloud stack in Git.
Cloud Security & Compliance
Zero-trust architecture, secrets management, VPC design, WAF setup, and compliance frameworks — SOC 2, ISO 27001, HIPAA, GDPR. Security baked in, not bolted on.
Stop Paying
for Idle
Resources.
Most companies overspend on cloud by 30–40% without knowing it. We audit your current usage, eliminate waste, right-size instances, and implement reserved pricing strategies that typically pay for our engagement within the first month.
- Right-sizing and Reserved Instance planning
- Spot and Preemptible instance strategies
- Auto-scaling to eliminate idle capacity
- Monthly cost reports with actionable insights
See Everything.
Miss
Nothing.
You can't fix what you can't see. We instrument your entire stack with Prometheus, Grafana, and OpenTelemetry — giving you real-time dashboards, intelligent alerting, and distributed traces that pinpoint problems before your users notice them.
- Prometheus + Grafana monitoring stack
- Distributed tracing with Jaeger / OpenTelemetry
- SLA dashboards and on-call alerting
- Log aggregation with ELK / Loki
The Numbers
Behind Our
Infrastructure.
Real results from real production systems — not benchmarks, not demos.
Production environments launched across AWS, Azure, and GCP. Every industry, every scale.
Across all managed client infrastructure over the past 3 years. Downtime is not in our vocabulary.
Average cloud bill reduction within 90 days of our infrastructure audit and optimization engagement.
Average time between production deployments for clients after we implement our CI/CD pipelines.
From Audit
to Production
in 30 Days.
A structured, low-disruption process designed to move fast without breaking things. We've refined this across 200+ cloud engagements — it works every time.
Infrastructure Audit
We map your stack, surface security gaps, cost waste, and bottlenecks. Full written report — free, no obligation.
Architecture Design
Target cloud architecture designed — network, compute, data, security model, and DR plan. All documented before provisioning.
Infrastructure Build
Kubernetes, CI/CD, monitoring, and security — all as code. Peer-reviewed, tested in staging before touching production.
Migration & Cutover
Blue-green migration, zero downtime. Automated rollback triggers. Both environments parallel until confidence is 100%.
Managed Operations
24/7 monitoring, incident response, cost reviews, security patching, and quarterly architecture improvements.
The Stack That
Powers It All.
We're cloud-agnostic and tool-agnostic. We pick whatever's right for your scale, team, and budget — not what's trendy or convenient for us.
Questions
Before You
Commit.
No pressure, no jargon. Here are the questions every engineering leader asks us before we start — answered honestly.
We use a blue-green migration strategy — your new cloud environment runs in parallel with your current one. Traffic shifts gradually (1% → 10% → 50% → 100%) with automated rollback triggers at each stage. If anything goes wrong, we roll back in under 60 seconds. We've done this 200+ times without a production incident.
Honestly, it depends on your team, your stack, and your use case. AWS has the widest service catalogue and best community resources. Azure wins if you're already in the Microsoft ecosystem (Active Directory, .NET, Office 365). GCP is exceptional for data-intensive workloads and Kubernetes (they invented it). We'll recommend the right one for your situation — not the one with the best reseller margin for us.
Most clients see measurable cost reduction within the first 30 days. The quickest wins — shutting down idle resources, right-sizing over-provisioned instances, and enabling Reserved Instances — typically happen in week one. The more strategic optimisations (spot instances, serverless migration, data transfer optimization) compound over 60–90 days. Our average client reduces their bill by 40%.
It means a human being is on-call for your infrastructure around the clock, 365 days a year. Our SLA is a 15-minute response to P1 incidents and a 2-hour resolution target. We have an automated monitoring layer that catches 80% of issues before they surface to users, and a team rotation that ensures nobody is burned out — so you get sharp, fresh eyes at 3am when it counts.
Never. You retain full ownership and admin access to every account, resource, and credential. We operate as an extension of your team — not a black box. All infrastructure is defined as code in your own Git repositories. If you ever want to bring management in-house or switch providers, you have everything you need to do so independently. We build for your autonomy, not your dependency on us.
Your Cloud.
Optimised.
This Month.
Tell us what you're running. We'll audit it, identify the gaps and the waste, and show you exactly what we'd do — for free, in writing, with no obligation to proceed.
$ dartsyn audit --env production
▶ Scanning 47 resources...
✓ Network topology mapped
✓ Security groups audited
⚠ 3 idle instances found
⚠ $1,240/mo potential savings
✓ Compliance check: SOC 2 ready
Report ready → audit_report.pdf
█